
Demos
2025
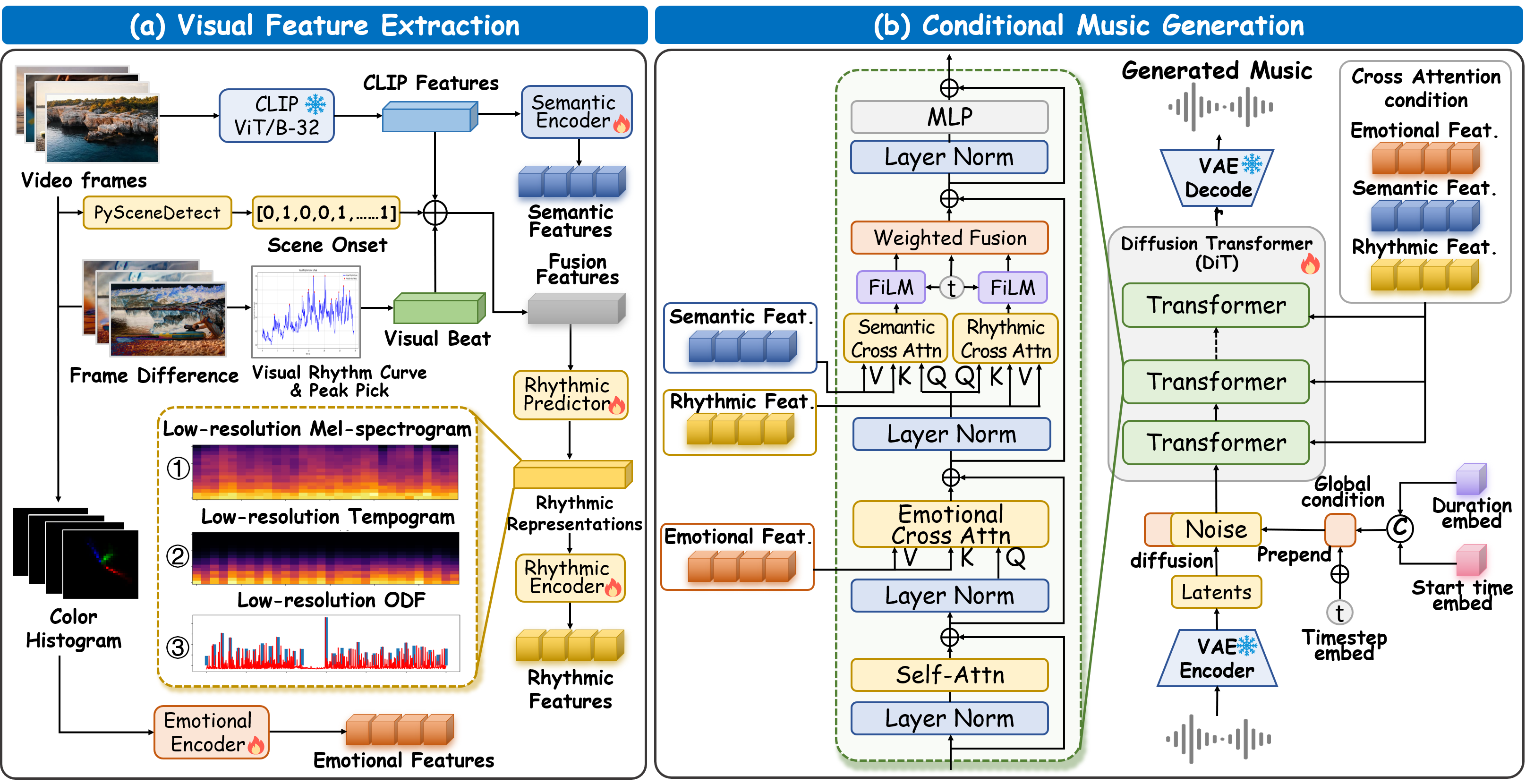
- Diff-V2M is a hierarchical diffusion model with explicit rhythmic modeling and multi-view feature conditioning, achieving state-of-the-art results in video-to-music generation. Diff-V2M comprises two core components: visual feature extraction and conditional music generation. For rhythm modeling, several rhythmic representations are evaluated, including low-resolution mel-spectrograms, tempograms, and onset detection functions (ODF), and a rhythmic predictor is devised to infer them directly from videos. To ensure contextual and affective coherence, semantic and emotional features are extracted as well. All features are incorporated into the generator via a hierarchical cross-attention mechanism, where emotional features shape the affective tone via the first layer, while semantic and rhythmic features are fused in the second cross-attention layer. To enhance feature integration, timestep-aware fusion strategies including feature-wise linear modulation (FiLM) and weighted fusion are introduced, allowing the model to adaptively balance semantic and rhythmic cues throughout the diffusion process.
- Accepted by the AAAI 2026.
- Paper link | code repository | demo page
2023
A Survey on Deep Learning for Symbolic Music Generation: Representations, Algorithms, Evaluations, and Challenges
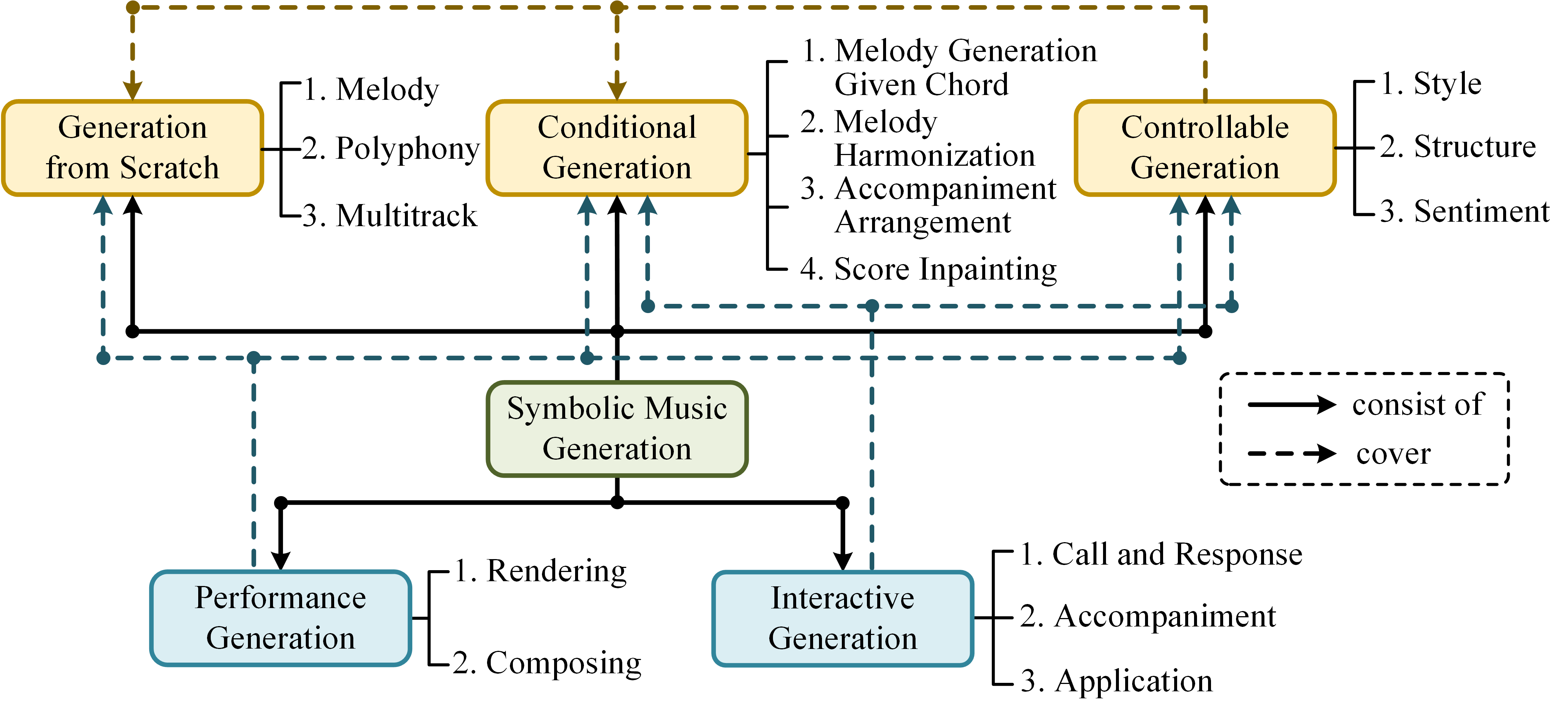
- This paper attempts to provide a task-oriented survey of symbolic music generation based on deep learning techniques, covering most of the currently popular music generation tasks. The distinct models under the same task are set forth briefly and strung according to their motivations, basically in chronological order.
- Accepted by the ACM Computing Surveys.
- Paper link
- MusER is a novel VQ-VAE-based model for generating symbolic music with emotion, which employs musical element-based regularization in the latent space to disentangle distinct musical elements, investigate their roles in distinguishing emotions, and further manipulate elements to alter musical emotions.
- Accepted by the AAAI 2024.
- Paper link | code repository | demo page
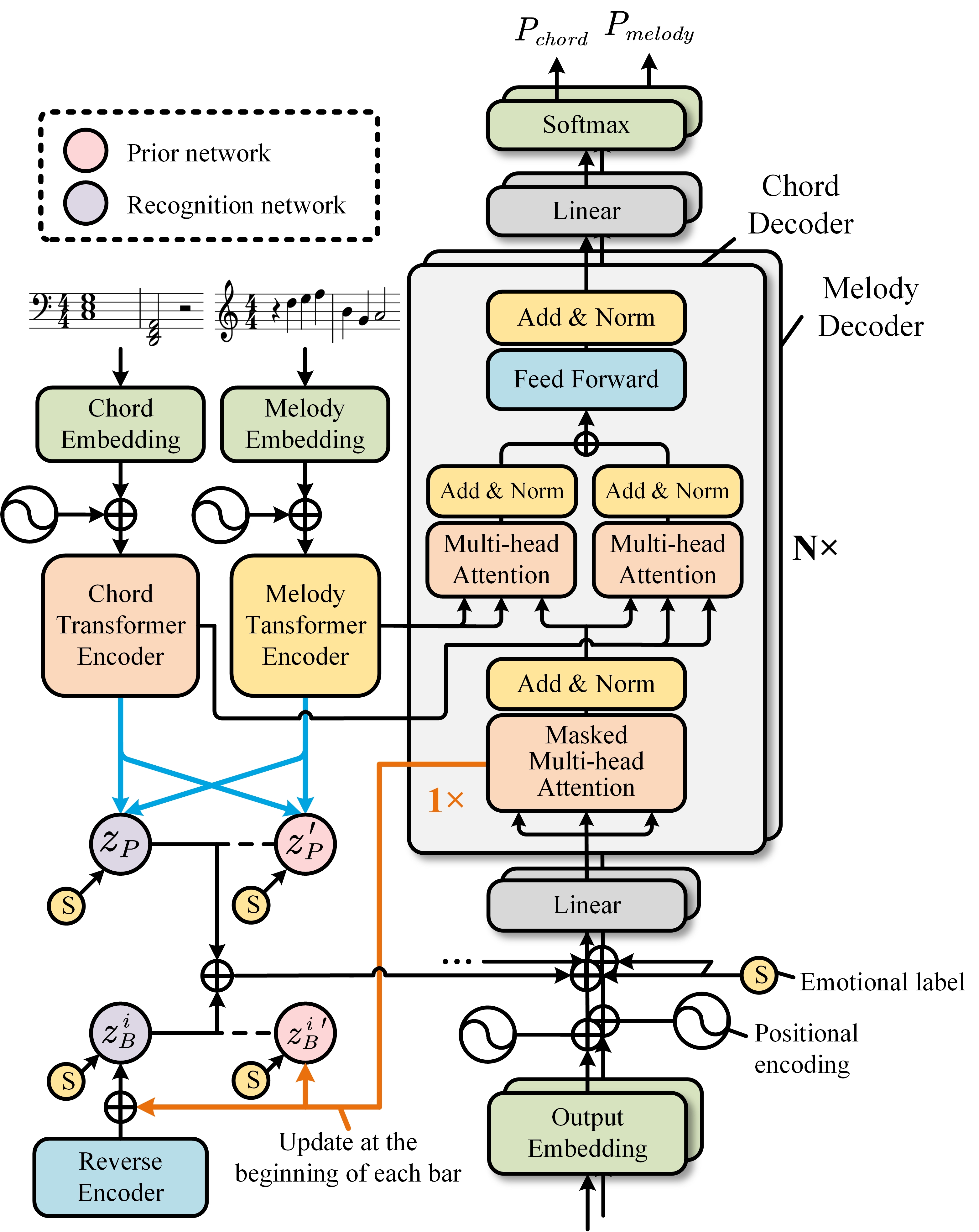
- EmoMusicTV is a transformer-based VAE that contains a hierarchical latent variable structure to model holistic properties of the music segments and short-term variations within bars. The piece- and bar-level emotional labels are embedded in their corresponding latent spaces to guide music generation. EmoMusicTV can adapt to multiple music generation tasks and performs well, e.g., melody harmonization, melody generation given harmony, and lead sheet generation.
- Accepted by the IEEE Transactions on Multimedia (TMM).
- Paper link | code repository | demo page
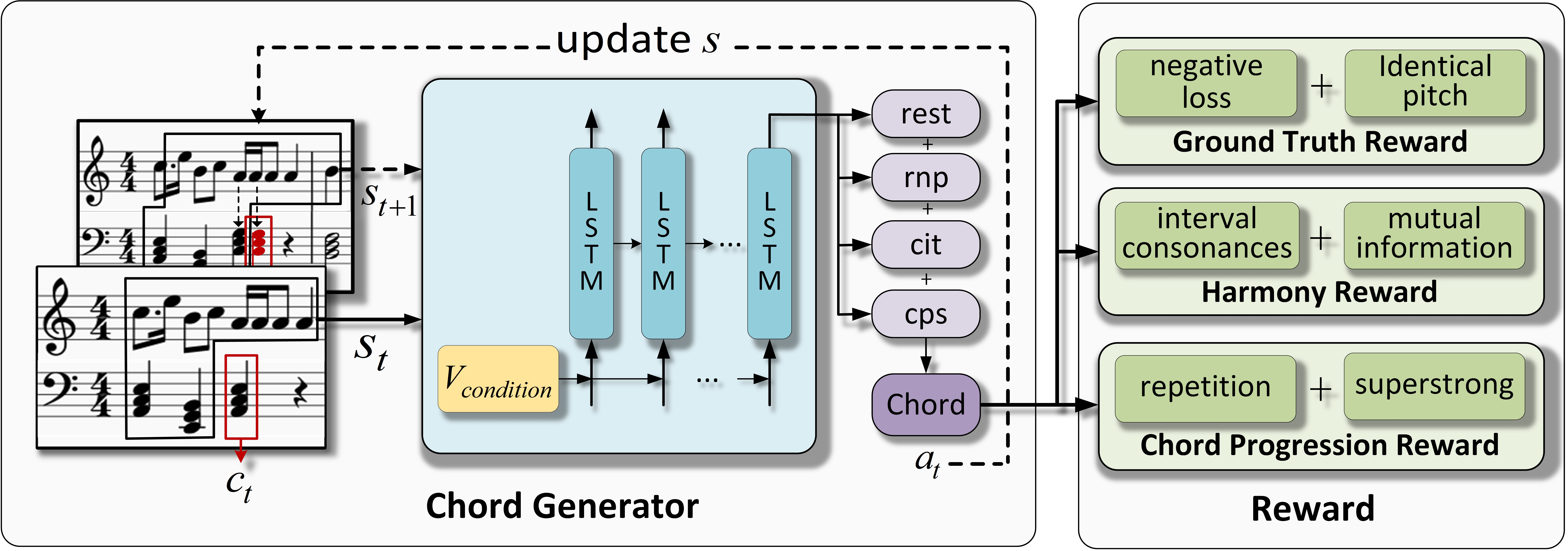
- RL-Chord is a novel melody harmonization system based on reinforcement learning (RL), which involves a newly designed chord representation, an improved conditional LSTM (CLSTM) model, and three well-designed reward modules. With the help of a pretrained style classifier, RL-Chord can also realize the unsupervised chord generation in Chinese folk style.
- Accepted by the IEEE Transactions on Neural Networks and Learning Systems (TNNLS).
- Paper link | code repository | demo page

- paper
To be added.